- 版本:v2.1.5
- 大小:128.07MB
- 支持度:87 %
- 更新:2026-07-30
软件特色介绍
umi-ocr 是一款开源、免费的离线 ocr(光学字符识别)软件,基于深度学习框架构建,无需联网即可在本地完成文字识别任务。它支持多种输入方式,包括截图、批量图片导入和 pdf 文档识别,并具备二维码扫描与生成功能。
免费开源:umi-ocr 的所有代码均开源,用户可免费使用、修改和优化,且不存在功能限制。
离线运行:所有识别过程均在本地完成,无需上传数据至云端,有效保护用户隐私,尤其适合处理机密文档或在没有网络的环境下使用。
高精度识别:内置多种语言识别库,支持简繁中文、英文、日文、韩文及常见欧洲语言,对复杂排版的文本(如竖排文字、表格、简单数学公式)也能精准识别。
多场景适用:支持截图 ocr、批量 ocr、pdf 识别、二维码处理及公式识别等多种功能,满足不同用户的多样化需求。
轻量化部署:软件无需安装,解压后即可使用,支持 windows 和 linux 系统(linux x64 系统需通过 docker 部署)。
软件功能
截图 ocr:
通过快捷键快速截取屏幕区域进行文字识别。
支持鼠标划选复制识别结果,并可在识别记录栏中编辑文字。
提供截图预览窗口,方便用户对比查看。
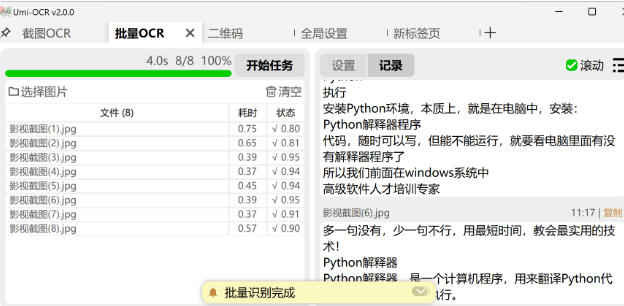
批量 ocr:
支持一次性导入多张图片进行批量识别,无数量上限。
识别结果可保存为 txt、json、markdown、csv 等多种格式。
提供文本后处理功能,可整理识别后的文本排版和顺序。
支持设置忽略区域,排除图片中的水印、页眉页脚等干扰内容。
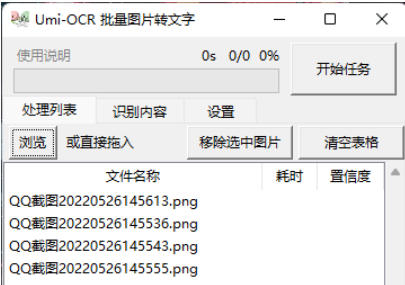
pdf 识别:
支持导入 pdf、xps、epub、mobi、fb2、cbz 等格式的文件。
可对扫描件进行 ocr 识别,或提取原有文本。
支持输出为双层可搜索的 pdf 文件,方便后续编辑和查找。
可设置忽略区域,排除页眉页脚的文字。
二维码处理:
支持截图、粘贴、拖入本地图片读取其中的二维码和条形码。
支持一图多码识别,兼容 19 种协议(如 url、文本、名片等)。
可生成符合多种协议的二维码。
公式识别:
提供简单的公式识别功能,可识别数学公式中的常见符号和表达式,并将其转化为可编辑的文本。
文本后处理:
提供多种排版解析方案,如多栏-按自然段换行、单栏-保留缩进等,使文本更符合阅读习惯。
支持忽略区域设置,适用于排除图片中的不想要的文字。
安装步骤